TTS 100% local : Kokoro, speaches GPU, et ce qui a cassé.
Six heures pour un pipeline vocal 100% local : Kokoro GPU, faster-whisper via Tailscale, un proxy Python, et un backtick fatal.
Partie 7 de la série OpenClaw — Le vrai TTS local, après avoir découvert qu’Edge TTS passe par Microsoft.
J’ai passé une nuit à faire parler mon agent IA. Pas métaphoriquement — littéralement.
Des vrais vocaux Telegram qui arrivent, sont transcrits en local, traités par un LLM local, et transformés en réponse audio par une voix locale. Zéro cloud. Zéro clé API qui tourne sur un serveur tiers.
Sauf que ça ne s’est pas passé comme prévu. Je pensais que ça prendrait deux heures. Il m’en a fallu six. Et la plupart des problèmes n’étaient pas là où je les attendais.
Le premier problème que personne ne mentionne
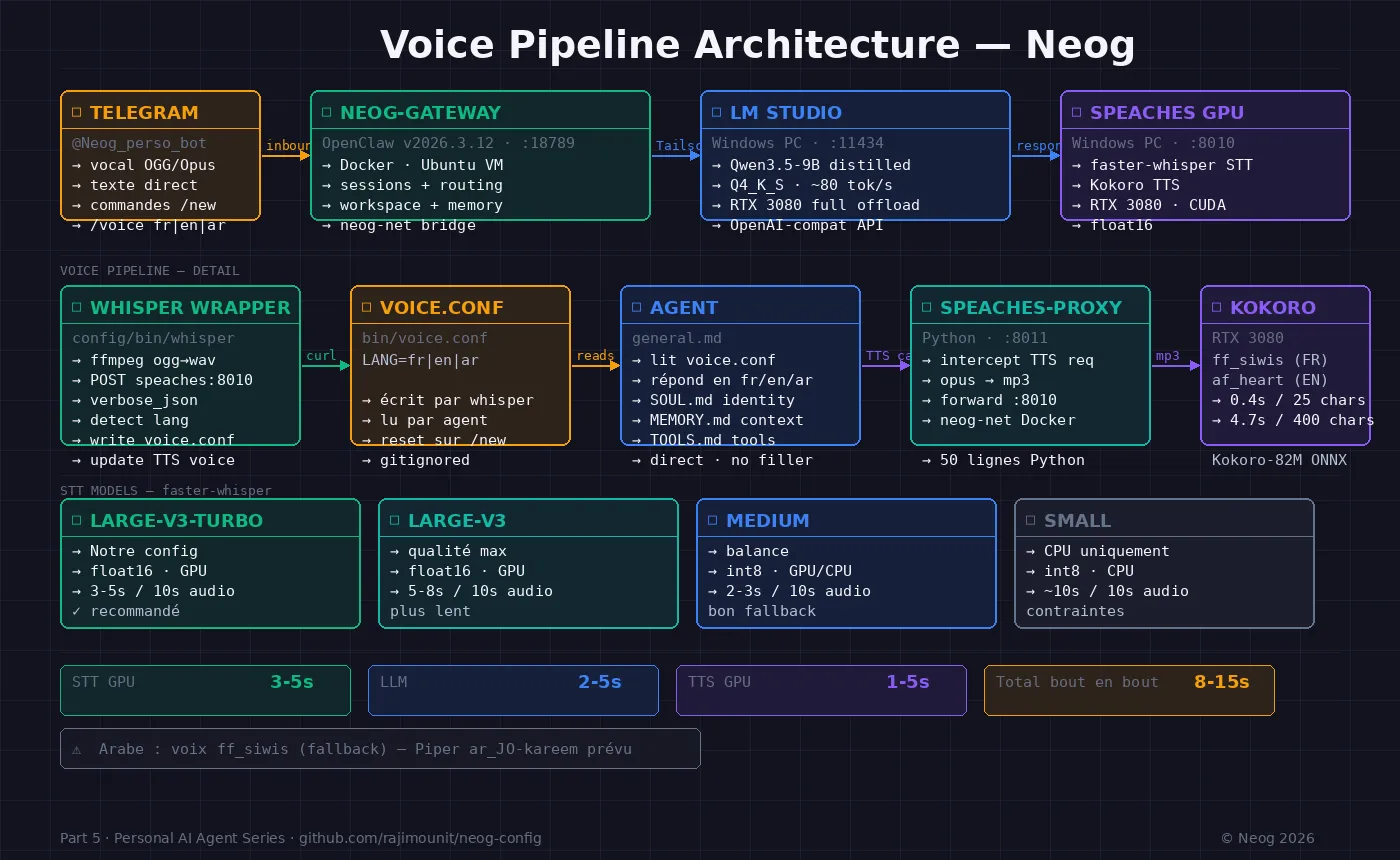
OpenClaw supporte le TTS via plusieurs providers : ElevenLabs, OpenAI, et Edge TTS. Pour le STT, il supporte des providers cloud ou des wrappers CLI locaux.
L’article précédent couvrait Edge TTS — fonctionnel, sans clé API, mais pas local : chaque synthèse passe par les serveurs Microsoft Azure Speech. L’objectif ici était de remplacer ça par Kokoro — un modèle TTS qui tourne sur mon propre GPU.
J’ai une instance speaches qui tourne sur mon PC Windows avec une RTX 3080. Speaches expose une API compatible OpenAI — parfait, OpenClaw sait parler à cette API. Plan : configurer speaches comme provider TTS dans OpenClaw.
Cinq minutes de config. Deux minutes de test. Et puis :
HTTP: 422 Unprocessable EntityEncore. Encore. Encore.
La leçon que personne n’écrit dans les tutoriels : OpenClaw envoie response_format: opus à son provider TTS pour les messages Telegram. L’Opus est requis pour les bulles vocales rondes. Et speaches ne supporte pas Opus.
Ce n’est pas un bug. Ce n’est pas une mauvaise config. C’est une incompatibilité de format documentée nulle part dans les deux projets combinés.
La solution qui ne devrait pas exister mais qui marche
Un micro-proxy Python. Cinquante lignes. Il s’intercale entre OpenClaw et speaches, intercepte chaque requête TTS, et remplace response_format: opus par response_format: mp3 avant de la transmettre.
if self.path == "/v1/audio/speech":
data = json.loads(body)
if data.get("response_format", "") in ("opus", "aac", ""):
data["response_format"] = "mp3"
body = json.dumps(data).encode()C’est la bonne vieille approche “shim” — une couche de traduction entre deux systèmes qui ne se parlent pas directement. Elle existe depuis les années 70. On l’utilise encore en 2026 pour faire parler Kokoro à Telegram.
Le résultat : Kokoro génère du MP3. Telegram reçoit un fichier audio au lieu d’une bulle vocale ronde. Fonctionnellement identique — l’audio joue pareil. Visuellement différent — une icône de téléchargement au lieu d’un bouton play inline.
J’ai accepté ce trade-off. La bulle ronde nécessite ElevenLabs ou OpenAI TTS. Zéro cloud. Zéro compromis.
Le GPU qui n’est pas là où on croit
Ma VM Ubuntu est sur une machine Windows avec une RTX 3080. Problème : la VM n’a pas accès au GPU. VirtualBox ne supporte pas le GPU passthrough natif dans cette configuration.
La solution intuitive : installer speaches avec CUDA dans la VM. Mauvaise piste.
La solution correcte : speaches tourne directement sur Windows avec Docker Desktop (latest-cuda), exposé sur le réseau Tailscale. OpenClaw dans la VM l’appelle via l’IP Tailscale du PC — exactement comme il appelle LM Studio.
VM (OpenClaw)
→ LM Studio sur PC Windows:11434 ✅ déjà fait
→ speaches GPU sur PC Windows:8010 ← même principeLe modèle conceptuel, c’est du remote inference — pas du GPU passthrough. Le GPU reste sur la machine hôte, l’API voyage sur le réseau local. Avec Tailscale, la latence est négligeable.
Résultat concret : transcription STT passe de 30 secondes (CPU dans la VM) à 3-5 secondes (RTX 3080 via réseau local).
Le problème de langue que j’ai créé moi-même
Une fois le pipeline vocal fonctionnel, j’ai voulu ajouter la détection automatique de langue. faster-whisper détecte la langue dans sa sortie verbose_json. Le plan : le wrapper STT écrit le code langue dans un fichier voice.conf, l’agent lit ce fichier, répond dans la bonne langue, Kokoro utilise la voix correspondante.
Simple. Sauf que j’ai créé le fichier voice.conf depuis le host Ubuntu. Et depuis l’intérieur du container Docker, le fichier n’existait pas.
La règle que j’aurais dû savoir : si un fichier doit être écrit par un process Docker, il doit être créé depuis l’intérieur de ce container. Pas depuis le host. Jamais.
Ce qui s’est passé entre 3h et 4h du matin
Le backtick.
OpenClaw version Docker a un bug peu documenté : il ajoute un backtick (`) en tête de openclaw.json à chaque démarrage. Ce caractère invalide le JSON. Chaque fois que je redémarrais le gateway pour appliquer une config, le fichier se corrompait silencieusement.
La détection a pris du temps parce que mes scripts Python failaient sans message d’erreur — json.load() lève une exception que j’absorbais avec un except: pass.
Fix définitif : un entrypoint wrapper dans Docker Compose qui strip le backtick avant de lancer le gateway. Une ligne de sed. Appliquée à chaque démarrage. Le genre de fix qui aurait dû prendre deux minutes si j’avais su chercher au bon endroit.
Ce que ça a coûté en temps
| Étape | Temps estimé | Temps réel |
|---|---|---|
| Config initiale | 30 min | 1h |
| STT fonctionnel | 30 min | 1h |
| TTS Kokoro (422) | 30 min | 2h |
| GPU remote STT | 20 min | 45 min |
| Détection langue | 30 min | 1h |
| Fix backtick | 5 min | 30 min |
| Total | ~3h | ~6h |
L’écart est réel. La plupart vient de problèmes que personne ne documente parce que personne d’autre n’a exactement ce setup.
Le résultat
À 4h du matin, le pipeline est complet.
Je parle en français dans Telegram. faster-whisper transcrit en 4 secondes avec une probabilité de détection langue à 0.99. L’agent lit voice.conf, voit LANG=fr, répond en français. Kokoro génère l’audio avec la voix ff_siwis. Le fichier MP3 arrive sur Telegram.
Je parle en anglais. Même pipeline. LANG=en. Kokoro utilise af_heart.
Aucune donnée n’a quitté mon réseau Tailscale.
Ce que j’ai appris
Sur l’incompatibilité de formats : Les projets open-source s’assemblent rarement parfaitement. La couche de traduction — shim, proxy, wrapper — est une décision d’architecture normale, pas une dette technique.
Sur le GPU remote : Le “GPU dans le cloud” et le “GPU sur un PC du même réseau” sont conceptuellement identiques du point de vue du code. L’un coûte 50€/mois, l’autre est déjà payé.
Sur Docker et les fichiers partagés : Les volumes montés ne sont pas transparents. Toujours créer les fichiers runtime depuis l’intérieur du container.
Sur le débogage nocturne : Les erreurs silencieuses coûtent cher. except: pass devrait être banni des scripts de diagnostic.
La prochaine étape : la voix arabe. Kokoro n’a pas de voix arabe — il faudra intégrer Piper avec ar_JO-kareem-medium. C’est un prochain article.
Partager cet article