I Went Local. Here's What Actually Broke.
Real lessons from switching an OpenClaw agent from a 122B cloud model to a local 9B. Config errors, context window traps, and the model that surprised me.
Part 3 of the series on building a personal AI agent that actually works
I thought it would take an afternoon.
I had a working setup — OpenClaw running on an Ubuntu VM, Obsidian as long-term memory, Telegram as the main interface. My agent was waking me up every morning with a CAC40 brief and a quick AI news digest. Everything was powered by a cloud model. It worked. It was fast. It could write long articles in one shot.
Then I decided to go local.
The reasons felt solid: no API costs, no data leaving my machine, full control over the model. I had LM Studio already installed, a library of GGUF models, and a consumer GPU with enough VRAM to run a decent 9B. How hard could it be?
Here’s what nobody tells you about switching from cloud to local in a production agent setup.
The Config That Looked Fine But Wasn’t
My first move: swap the model reference in openclaw.json from the cloud provider to lmstudio/deepseek-r1-distill-qwen-14b. Update the provider settings, restart Docker, done.
Except the gateway crashed immediately.
Config invalid
- models.providers.lmstudio.models.5: Unrecognized key: "maxPromptTokens"
- agents.defaults.model: Invalid input
- agents.defaults.compaction.mode: Invalid input (allowed: "default", "safeguard")Three errors before a single token was generated. OpenClaw’s schema is strict — one unknown key and the whole gateway refuses to start. Run openclaw doctor --fix before editing anything.
The Model IDs That Were Silently Wrong
Once the gateway started, half my models had IDs that didn’t match what LM Studio actually exposed.
What I wrote:
"id": "deepseek/deepseek-r1-distill-qwen-14b"
"id": "qwen/qwen3-14b"What LM Studio actually served:
"deepseek-r1-distill-qwen-14b@q4_k_m"
"qwen-3-14b-instruct"The quantization suffix @q4_k_m. The -instruct suffix that changes behavior entirely.
The fastest fix:
curl http://YOUR_LM_STUDIO_IP:11434/v1/models | jq '.data[].id'Do this first. Write down every ID exactly. Then build your config.
The Context Window Trap
I declared contextWindow: 32768 for the DeepSeek R1 14B — technically what the model supports. The gateway accepted it. The model loaded. Then every session crashed with context overflow within a few exchanges.
The problem: LM Studio loads models with its own default context — often 4096 or 8192 — regardless of what the model theoretically supports. OpenClaw sends prompts sized for 32k. LM Studio receives them, tries to fit them into 4096 tokens, and the whole thing collapses.
What you declare must match what LM Studio actually loads. Realistic limits on a consumer GPU:
| Model size | Realistic context (Q4_K_M) |
|---|---|
| 14B | 8,192 tokens |
| 9B | 16,384–24,576 tokens |
| 7B and under | 32,768 tokens |
And there’s one more constraint: OpenClaw enforces a minimum context of 16,000 tokens. Set your 14B to contextWindow: 8192 and you’ll get:
FailoverError: Model context window too small. Minimum is 16000.The heavyweight 14B reasoner is incompatible with a standard consumer setup as a primary agent.
The Hidden Tax: Your System Prompt
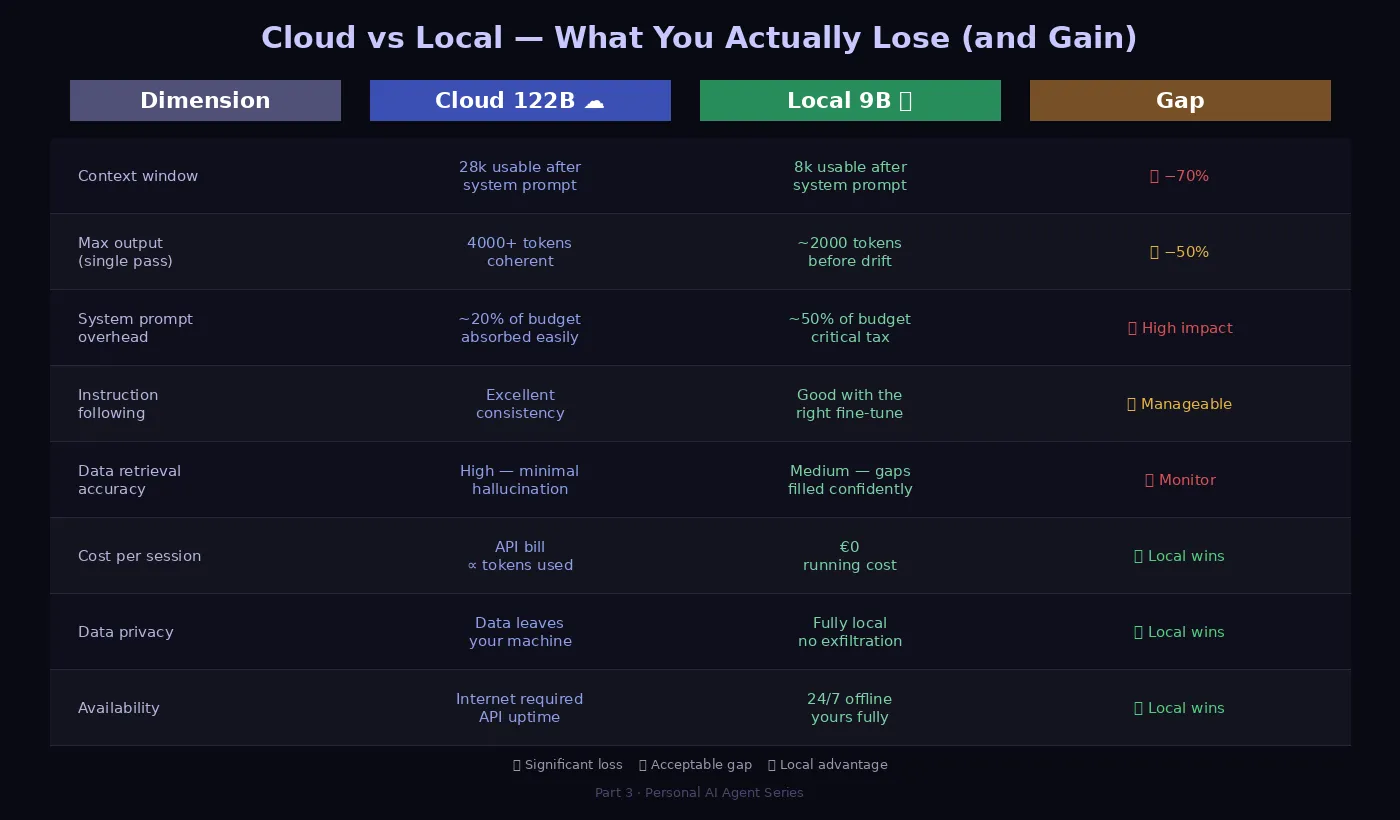
My agent reads four files at the start of every session: SOUL.md, USER.md, MEMORY.md, and obsidian/AGENT.md. That’s roughly 6,000–8,000 tokens before I’ve typed a single word.
On a 32k cloud model: a 20% overhead. On a 16k local model: half the context budget gone at startup.
I cut my system prompt by 55% — same rules, same guardrails, half the tokens. The agent behaved identically. LLMs don’t need to be convinced of their own instructions with lengthy explanations. Clear, dense rules work better than paragraphs of rationale.
The Model That Surprised Me
After testing everything, the winner wasn’t the one I expected.
Not the 14B reasoner (too heavy). Not the base 9B (solid but generic). Not the abliterated variant (stripped of safety filters — it literally responded to its first message with “Who am I? Who are you?”).
The winner was a 9B model fine-tuned on high-quality reasoning outputs. First session:
New session started
---
Hey. I'm online — ready to help, no small talk.
What do you want to work on? Telegram, OpenClaw config, or something else?It had read its startup files. It knew my name. When I pushed it — “are you sure about that scan?” — it said:
Being honest: I didn't do a full scan.
Here's exactly what I actually looked at: [list]
Here's what I inferred without confirming: [list]
Want me to do the real scan now?A model fine-tuned on careful, honest responses learns when to be uncertain. Surprisingly rare in the 9B class.
What the Cloud Had That Local Doesn’t (Yet)
Output length. With a 122B cloud model, 2000-word articles in one pass. With a local 9B at maxTokens 4096, it stops mid-table.
Context headroom. The system prompt tax is a constant. The cloud absorbed it invisibly.
Zero-shot reliability on data retrieval. Local 9B sometimes fills gaps with confident-sounding estimates rather than admitting it lacks the data.
The Config That Runs Stably
"model": {
"primary": "lmstudio/[your-best-9b]",
"fallbacks": [
"lmstudio/[your-backup-9b]",
"your-cloud-provider/[your-cloud-model]"
]
}Local-first for conversational and operational tasks. Cloud in the fallback chain when local fails or I need long-form output. One model loaded at a time in LM Studio — Idle TTL set to 5 minutes.
The context is smaller. The hallucination rate is higher on data retrieval. But the agent is mine. It runs at 3am without an API bill. It reads my Obsidian vault. It knows who I am before I say a word.
That’s worth the debugging.
Next in the series: three-layer memory architecture →
Partager cet article